【Passport to AI Era Special Edition】The Global AI Training Pivot: Positioning Sydney as a Potential Strategic Infrastructure Nexus

The release of DeepSeek V4 has undoubtedly sent shockwaves through the technology community. While most analyses focus on leaps in model capabilities, architectural innovations, or expanded application scenarios, we propose a different perspective: this time, let’s shift our gaze from “what the model can provide” to “what is provided to the model.”
DeepSeek V4 的發布,無疑在技術圈投下了一顆震撼彈。當多數分析聚焦於模型能力的躍升、架構的創新或應用場景的拓展時,我們想換一個視角:這一次,讓我們把目光從「模型能提供什麼」,轉向「什麼提供給模型」。
The technical pipeline of large language models can be broadly divided into two ends: inference and training. The story on the inference side has already been told brilliantly by DeepSeek V4: when executing the same task, V4-Pro requires only 27% of the FLOPs per token for single-token inference compared to V3.2, while KV Cache occupancy is compressed to just 10% [1]. This means that the same hardware resources can now handle denser inference requests—or, put differently, the barrier to achieving equivalent inference performance has been substantially lowered.
大語言模型的技術鏈路,粗淺可拆為推理(Inference)與訓練(Training)兩端。推理端的故事,DeepSeek V4 已經講得足夠精彩:V4-Pro 在執行同一任務時,對單 Token 推理的 FLOPs 需求僅為 V3.2 的 27%,KV Cache 佔用更壓縮至 10%[1]。這意味著,同樣的硬體資源,現在能承載更密集的推理請求;或者说,達成同樣的推理效果,門檻已大幅降低。

Intuitively, this might seem to signal a “subtraction” in compute demand. However, the Jevons Paradox from economics reminds us that when resource efficiency improves and unit costs decline, total consumption often does not decrease—instead, it may rise due to the explosion of application scenarios and expansion of the user base. The efficiency leap on the inference side is likely opening the door to far broader applications.
直覺上,這似乎預示著算力需求的「減法」。但經濟學裡的「傑文斯悖論」(Jevons Paradox)提醒我們:當資源使用效率提升、單次成本下降,往往不會導致總消耗減少,反而可能因為應用場景的爆發與用戶規模的擴張,推高整體需求。推理端的效率躍遷,很可能正打開一扇更廣闊的應用之門。
Yet today, we want to focus on the other end: training.
然而,今天我們想聚焦的,是另一端——訓練。
Scale Laws Still Hold: The “Arms Race” in Parameters and Data // 規模法則依然有效:參數與數據的「軍備競賽」 #
Reviewing DeepSeek’s version evolution reveals a clear trajectory:
翻開 DeepSeek 的版本演進表,一條清晰的曲線浮現:
| Model Version 模型版本 | Release Date 發布時間 | Total Parameters 總參數量 | Pre-training Data Volume 預訓練數據量 |
|---|---|---|---|
| DeepSeek-V2 | 2024-05-06 | 236B | 8.1T tokens |
| DeepSeek-V3 | 2024-12-26 | 671B | 14.8T tokens |
| DeepSeek-V4-Pro | 2026-04-24 | 1.6T (1600B) | 33T tokens |
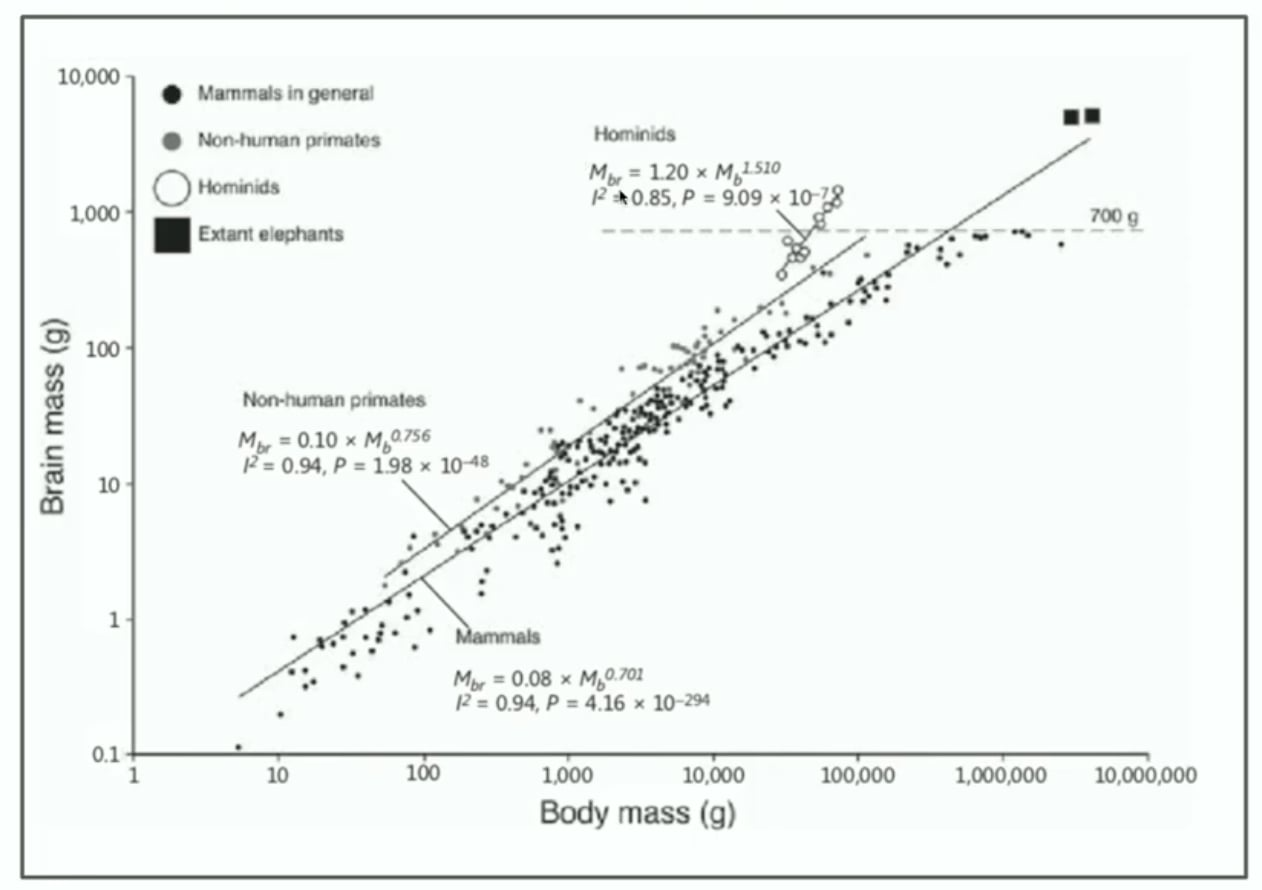
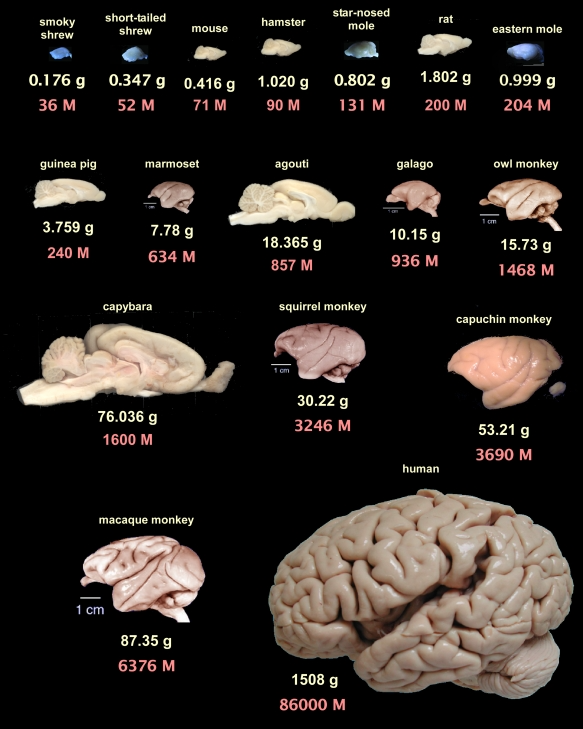
Parameters have surged from 236B to 1.6T, while pre-training data has expanded from 8.1T to 33T tokens. This is not merely numerical growth—it represents iterative capability enhancement. This trend resonates intriguingly with findings in neuroscience: the cognitive capacity of primates correlates nearly linearly with neuron count and brain volume [2][3]. In the realm of artificial intelligence, Scale Laws have not only remained valid but continue to raise the compute barrier with even greater force.
參數量從 236B 躍升至 1.6T,預訓練數據量從 8.1T tokens 擴張至 33T tokens。這不僅是數字的膨脹,更是能力的疊代。這與腦科學研究的結論形成有趣呼應:靈長類動物的認知能力,與其神經元數量、腦容量呈現近線性相關[2][3]。在人工智慧的領域,Scale Law 非但沒有失效,反而以更強悍的姿態,持續拉升著算力的壁壘。
The stronger the model, the "heavier" the training. This leads to a direct business implication: **resource demands during the training phase are escalating along an exponential curve.**
模型越強,訓練越「重」。這帶來一個直接的商業命題:訓練階段的資源需求,正在以指數級曲線攀升。
The Structure of Training Costs: More Than Just a Chip Game // 訓練成本的結構:不只是芯片的遊戲 #
According to the influential report The Rising Costs of Training Frontier AI Models [4], which analyzes pre-training costs for large models (assuming self-built infrastructure), the cost structure breaks down approximately as follows:
根據 著名的《THE RISING COSTS OF TRAINING FRONTIER AI MODELS》[4]對大模型預訓練成本的分析(假設自建基礎設施),成本結構大致如下:
- Chips 芯片 (GPU/ASIC): 44%
- Server components 服務器組件 (CPU, memory, etc.): 29%
- Networking equipment 網絡設備: 17%
- Energy 能源: 9%
At first glance, chips remain the largest component. However, when server components, networking, and energy are combined, they account for over 55%. More critically, as cluster scales expand from thousands to tens of thousands of GPUs, the marginal cost weight of power supply, thermal cooling, and network topology will only continue to rise.
乍看之下,芯片仍是最大頭。但若將服務器組件、網絡與能源相加,占比已超過 55%。更關鍵的是,隨著集群規模從千卡、萬卡走向十萬卡,電力供應、散熱冷卻、網絡拓撲的邊際成本權重,只會越來越高。

Here lies a frequently overlooked characteristic: training workloads are inherently insensitive to latency. Unlike inference, which requires millisecond-level responsiveness, training can tolerate longer task cycles. This means training infrastructure need not compete for space in traditional cloud hubs characterized by tight power grids, geopolitical congestion, and elevated costs. The siting of training clusters now has room to “vote with their feet”—locations with lower geopolitical risk, more controllable energy costs, and greater long-term policy stability may well become the next-generation footholds for AI infrastructure.
這裡有一個常被忽略的特性:訓練任務對延時(Latency)天生不敏感。與推理端需要毫秒級響應不同,訓練可以容忍更長的任務週期,這意味著它不必擠在用電緊張、地緣擁擠、成本高昂的傳統雲端樞紐。訓練集群的選址,從此有了「用腳投票」的空間——哪裡的地緣風險更低、能源成本更可控、長期政策更穩定,哪裡就可能成為下一代 AI 基礎設施的落腳點。
From Technical Marvel to Commercial Essence: The Coordinates of Extreme ROI // 從技術奇蹟到商業本質:極致投入產出比的坐標 #
In the real commercial world, scientific marvels achieved regardless of cost may make it into academic papers, but they rarely reshape the course of civilization. What truly drives technological adoption and industrial transformation has always been extreme return on investment (ROI). When training costs become a core constraint on model iteration, site selection ceases to be merely a technical decision for IT departments—it becomes a strategic imperative central to long-term competitiveness.
在真實的商業世界裡,不計成本的科學奇蹟,或許能寫進論文,但很難改寫文明進程。真正推動技術普及與產業變革的,從來是極致的投入產出比(ROI)。當訓練成本成為模型迭代的核心約束,選址就不再只是 IT 部門的技術決策,而是關乎長期競爭力的戰略命題。
Thus, a long-underestimated coordinate begins to emerge: Sydney.
於是,一個長期被低估的坐標開始浮現:悉尼。
### Why Sydney? // 為什麼是悉尼?
A Geopolitical “Safe Harbor” Australia offers a mature rule of law, stable governance, and—amid today’s increasingly tense global landscape—a geographic position distant from major conflict hotspots. It remains one of the few developed economies capable of mitigating geopolitical risk simultaneously on multiple fronts. For AI training infrastructure, which entails long construction cycles and substantial capital commitment, policy certainty and asset security represent more foundational strategic considerations than short-term cost savings.
地緣政治的「避風港」 澳大利亞具備成熟法治、穩定政局,且在今日世界局勢日益緊張的當下有遠離主要衝突熱點的地理位置,是全球少數能同時規避地緣風險的發達經濟體。對於建設週期長、資本投入大的 AI 訓練基礎設施,政策確定性與資產安全,是比短期成本更底層的戰略考量。
Dual Advantages of Renewable Energy: Cost and Compliance Australia’s abundant solar and wind resources support competitively priced renewable energy. This not only directly reduces the energy expenditure component of training costs but also aligns with global technology enterprises’ commitments to carbon reduction. In the context of green supply chain trends, this serves as an implicit passport to future-proof operations.
可再生能源的成本與合規雙重優勢 澳洲豐富的太陽能與風能資源,可支援具價格競爭力的可再生能源。這不僅直接降低訓練成本中的能源支出,更契合全球科技企業對節能減碳的要求,在綠色供應鏈趨勢下成為隱形通行證。
Climate-Driven Cooling Dividends Sydney’s temperate maritime climate significantly extends the periods during which data centers can leverage natural cooling, markedly reducing reliance on mechanical refrigeration. For large-scale clusters where thermal management costs constitute an increasingly significant portion of operational expenditure, this translates into tangible efficiency gains and long-term cost resilience.
氣候賦予的冷卻紅利 悉尼溫和的海洋性氣候,大幅延長數據中心可利用自然冷卻的時段,顯著降低對機械製冷的依賴。對於散熱成本佔比日益提升的大規模集群,這意味著可觀的運營效率優勢與長期成本韌性。
Robust Infrastructure and Talent Ecosystem As a leading technology and financial hub in the Asia-Pacific region, Sydney boasts a comprehensive submarine cable network enabling efficient connectivity to major global markets. Concurrently, its mature pool of engineering talent and established data center industry ecosystem can provide end-to-end support—from design and construction to operations and maintenance—for ultra-scale AI clusters.
基礎設施與人才生態的完備性 作為亞太科技與金融樞紐,悉尼擁有完善的海底光纜網絡,可高效連接全球主要市場;同時,當地成熟的工程技術人才與數據中心產業鏈,能為超規模 AI 集群提供從設計、建設到運維的全週期支援。
Conclusion: The Next Stop in the Compute Arms Race // 結語:算力軍備競賽的下一站 #
As the AI competition enters a new phase of “compute arms race,” the decisive factors are no longer limited to innovations in model architecture—they increasingly hinge on strategic infrastructure deployment. DeepSeek V4, with its 1.6 trillion parameters and 33 trillion tokens of training data, reaffirms the resilience of Scale Laws and compels the industry to reconsider the cost structure and geographic logic underpinning the training phase.
當 AI 競賽進入「算力軍備競賽」的新階段,勝負手不再只是模型架構的創新,更是基礎設施的戰略佈局。DeepSeek V4 用 1.6 萬億參數與 33 萬億 tokens 的事實,再次驗證了 Scale Law 的韌性,也倒逼產業重新思考訓練端的成本結構與地理邏輯。
Technological breakthroughs must ultimately return to commercial fundamentals. Extreme ROI remains the authentic engine driving civilizational progress. And when compute power becomes the new era’s “oil,” the locations capable of refining it more safely, economically, and sustainably are precisely those poised to become the nexuses of the next AI wave.
技術的突破,終究要回歸商業的本質。極致的投入產出比,才是驅動文明進程的真實引擎。而當算力成為新時代的「石油」,哪裡能更安全、更經濟、更可持續地提煉它,哪裡就可能成為下一輪 AI 浪潮的樞紐。
Sydney may well be positioned at the coordinates of that nexus.
悉尼,或許就在這個樞紐的坐標上。
References / 參考資料
[1] DeepSeek-AI, DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
[2] Herculano-Houzel, S., The Human Brain in Numbers: A Linearly Scaled-up Primate Brain https://pmc.ncbi.nlm.nih.gov/articles/PMC2776484/
[3] Manger, P. R. et al., The Evolution of Large Brain Size in Mammals: The ‘Over-700-Gram Club Quartet’ https://doi.org/10.1159/000351975
[4] Epoch AI, The Rising Costs of Training Frontier AI Models https://arxiv.org/pdf/2405.21015
© Chung-Hao Lee. All Rights Reserved.
All content on this webpage—including but not limited to text, images, design, code, and multimedia materials—is protected under the international copyright treaties. Unauthorized reproduction, modification, distribution, public transmission, or commercial use is strictly prohibited. Legal action will be taken against infringement.
© 李崇豪。保留所有權利。
本網頁之內容(包括但不限於文字、圖片、設計、程式碼及多媒體素材)均受國際著作權條約保護。未經書面授權,嚴禁任何形式之複製、改作、散布、公開傳輸或商業利用。侵權者將依法追訴。